Teaching Human Language to a Computer
September 1, 2017

Longshaokan (Marshall) Wang, PhD Candidate
September 1, 2017
Longshaokan (Marshall) Wang, PhD Candidate
Have you ever learned to write code? If so, you were learning a “computer language.” But, have you ever considered the reverse; teaching a computer to “understand” a human language? With the advancement of machine learning techniques, we can now build models to convert audio signals to texts (Automatic Speech Recognition), detect emotions carried by sentences (Sentiment Analysis), identify intentions from texts (Natural Language Understanding), translate texts from one language to another (Machine Translation), synthesize audio signals from texts (Text-To-Speech) and more! In fact, you probably have already been using these models without knowing because they are the brains of the popular artificial intelligence (AI) assistants such as Amazon’s Alexa, Google Assistant, Apple’s Siri, Microsoft’s Cortana, and most likely Iron Man’s Jarvis. If you have ever wondered how these AI assistants interact with you, then you are in luck! We are going to take a high-level look at how these models are built.
Many of the language-processing tasks listed above use variations of a machine-learning model called Recurrent Neural Network (RNN). But, let’s start from the very beginning. Say you spotted an animal you haven’t seen before, and you attempt to classify it. Your brain is implicitly considering multiple factors (or features): Is it big? Does it make a noise? Does it have a tail?, etc. You weight these factors differently because maybe the color of its fur is not as important as the shape of its face. Then, your guess will be the “closest” animal you know. A machine-learning model for classification works similarly. It maps a set of input features (e.g., big, purrs, has a tail, …) to a classification label (cat). First, the model needs to be trained using samples with correct labels, so that it knows what features correspond to each label. Then, given the features of a new sample, the model can assign it to the “closest” label it knows.
A simple example of a classification model is a perceptron. This model uses a weighted sum of the input features to produce a binary classification based on whether the sum passes a threshold:

[1]
But a perceptron is too simple for many tasks, such as the “Exclusive Or (XOR)” problem. In XOR problems with 2 input variables, the correct classification is 1 if only one input variable is 1, and 0 otherwise:
| Values of input variables A and B | True output/correct classification |
|---|---|
| A = 0, B = 0 | 0 |
| A = 1, B = 0 | 1 |
| A = 0, B = 1 | 1 |
| A = 1, B = 1 | 0 |
However, this classification rule is impossible for a perceptron to learn. To see this, note that if there are only two input features, a perceptron essentially draws a line in the plane to separate the 2 classes, and in the XOR problem, a line can never classify the labels correctly (separate the yellow and gray dots):

[2]
To handle more complicated tasks, we need to make our model more flexible. One method is to stack multiple perceptrons to form a layer, stack multiple layers to form a network, and add non-linear transformations to the perceptrons:

[3]
The result is called an Artificial Neural Network (ANN). Instead of learning only a linear separation, this model can learn extremely complicated classification rules. We can increase the number of layers to make the model “deep” and more powerful, which we refer to as a Deep Neural Network (DNN) or Deep Learning.
Despite the flexibility of the DNN model, language processing remains a challenging classification task, however. For starters, sentences can have different lengths. In cases like Machine Translation, the output is not just a single label. What’s more, how can we train a model to extract useful linguistic features on its own? Just think about how hard it is for a human to become a linguist. So, to handle language processing, we need a few more twists on our DNN model.
To deal with the variable lengths of sentences, one can employ a method known as word embedding. Here, each word of a sentence is processed individually and mapped to a numeric vector of a fixed length. A good word embedding tends to put words with related meanings, such as “dolphin” and “SeaWorld,” close to one another in the vector space and words with distinct meanings far apart:

[4]
The embeddings are then fed to the DNN for classification.
But a word’s meaning and function also depend on its context in the sentence! How can we preserve the context when processing a sentence word by word? Instead of using only the current word as our DNN’s input, we also use the output of our DNN for the previous word as an additional input. The resulting structure is called a Recurrent Neural Network (RNN) because the previous output becomes part of the current input:
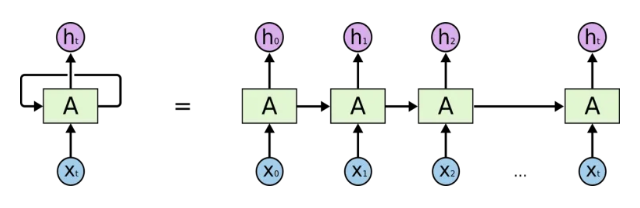
[5]
Now we know how to make our model “read” a sentence, but how do we format all the language-processing tasks as classification problems? It’s straightforward in Sentiment Analysis, where we use the output of an RNN for the last word as a summary for the sentence and add a simple classification model on top of the summary. The labels can be [“positive”, “neutral”, “negative”] or [“happy”, “angry”, “sad,” …]. In Machine Translation, we have an encoder RNN and a decoder RNN. The encoder reads and summarizes the sentence in language A; the decoder sequentially generates the translation word-by-word in language B. Given what you’ve learned so far, can you figure out how to use a RNN for Natural Language Understanding, Automatic Speech Recognition, and Text-To-Speech?
On this journey, we started with the basic classification model, the perceptron, and finished with the bleeding-edge classification models that can process human language. We have peeked into the brains of the AI assistants. Exciting research in language processing is happening as we speak, but there is still a long road ahead for the AI assistants to converse like humans. Language processing is, as mentioned before, not easy. At least next time you get frustrated with Siri, instead of yelling “WHY ARE YOU SO DUMB?” you can yell “YOU CLASSIFIED MY INTENTION WRONG! DO YOU NEED A BETTER EMBEDDING?”
References
[1] Programming a Perceptron in Python, 2013, Danilo Bargen.
[2] A deep learning tutorial: from perceptrons to deep networks, 2014, Ivan Vasilev.
[3] Overview of artificial neural networks and its applications, 2017, Jagreet.
[4] Wonderful world of word embeddings: what are they and why are they needed?, 2017, Madrugado.
[5] Understanding LSTM networks, 2015, Colah.
Marshall is a PhD Candidate whose research focuses on artificial intelligence, machine learning, and sufficient dimension reduction. We asked a fellow Laber Labs colleague to ask Marshall a probing question.
If you were running a company in Boston and had summer interns coming from out of town, what would be the best way to scam some money off of them? —James Gilman
Call my company Ataristicians and ask for seed money.
Just kidding. On a more serious note, if I were a scammer, I would take advantage of the fact that in Boston, gifting weed is legal but selling is not. The way transaction works is that the buyer would “accidentally” drop his money and then pick up the “gift bag” from the seller. The employees of my company would go to all the intern events, establish contacts with the interns, find the potential customers, and pose as discrete weed dealers. Then we would simply put garbage in the gift bag and take the interns “dropped” money. Nothing illegal with gifting garbage. Those interns can’t find help from the police. And because they came from out of town, they are unlikely to have connections with local gangs. Now, if we want to make more money, we would record the whole price negotiations and the transactions, then blackmail the interns, threatening to email the recordings to their managers and ruin their careers.
This is Marshall’s second post! To learn more about his research, check out his first article here!